
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
Tags
- 벌크 연산
- 타임리프
- JPQL
- Bean Validation
- 기본문법
- 프로젝트 환경설정
- 트위터
- 스프링
- 검증 애노테이션
- 타임리프 문법
- 로그인
- JPA 활용 2
- 김영한
- Spring Data JPA
- 일론머스크
- 스프링 mvc
- 불변 객체
- 값 타입 컬렉션
- JPA
- 컬렉션 조회 최적화
- 임베디드 타입
- 예제 도메인 모델
- API 개발 고급
- 페이징
- QueryDSL
- 스프링 데이터 JPA
- JPA 활용2
- jpa 활용
- 실무활용
- 스프링MVC
Archives
- Today
- Total
RE-Heat 개발자 일지
[Spring Data JPA] [6] 스프링 데이터 JPA 분석 본문
실전! 스프링 데이터 JPA - 인프런 | 강의
스프링 데이터 JPA는 기존의 한계를 넘어 마치 마법처럼 리포지토리에 구현 클래스 없이 인터페이스만으로 개발을 완료할 수 있습니다. 그리고 반복 개발해온 기본 CRUD 기능도 모두 제공합니다.
www.inflearn.com
인프런 김영한 님의 강의를 듣고 작성한 글입니다.
[1] 스프링 데이터 JPA 구현체 분석
SimpleJpaRepository

- @Repository 적용: JPA 예외를 스프링이 추상화한 예외로 변환
- @Transactional(readOnly = true)
- 데이터를 단순히 조회만 하고 변경하지 않는 트랜잭션에서 readOnly = true 옵션을 사용하면 플러
시를 생략해서 약간의 성능 향상을 얻을 수 있음
- 데이터를 단순히 조회만 하고 변경하지 않는 트랜잭션에서 readOnly = true 옵션을 사용하면 플러
- @Transactional 트랜잭션 적용
- JPA의 모든 변경은 트랜잭션 안에서 동작
- 스프링데이터 JPA는 변경(등록, 수정, 삭제) 메서드를 트랜잭션 처리
- 서비스계층에서 트랜잭션을 시작하지 않으면 리파지토리에서 트랜잭션 시작
- 서비스계층에서 트랜잭션을 시작하면 리파지토리는 해당트랜잭션을 전파받아서 사용
- 그래서 스프링데이터 JPA를 사용할 때 트랜잭션이 없어도 데이터등록, 변경이 가능했음
- (사실은 트랜잭션이 리포지토리 계층에 걸려있는 것)
- @Transcational(readOnly=true)가 전체적으로 적용되지만, 각 메소드에 붙어있는 @Transactional 우선순위가 더 높다. 그래서 등록, 수정, 삭제 메서드는 읽기 전용이 아니므로 따로 붙여 줌.
save()메서드
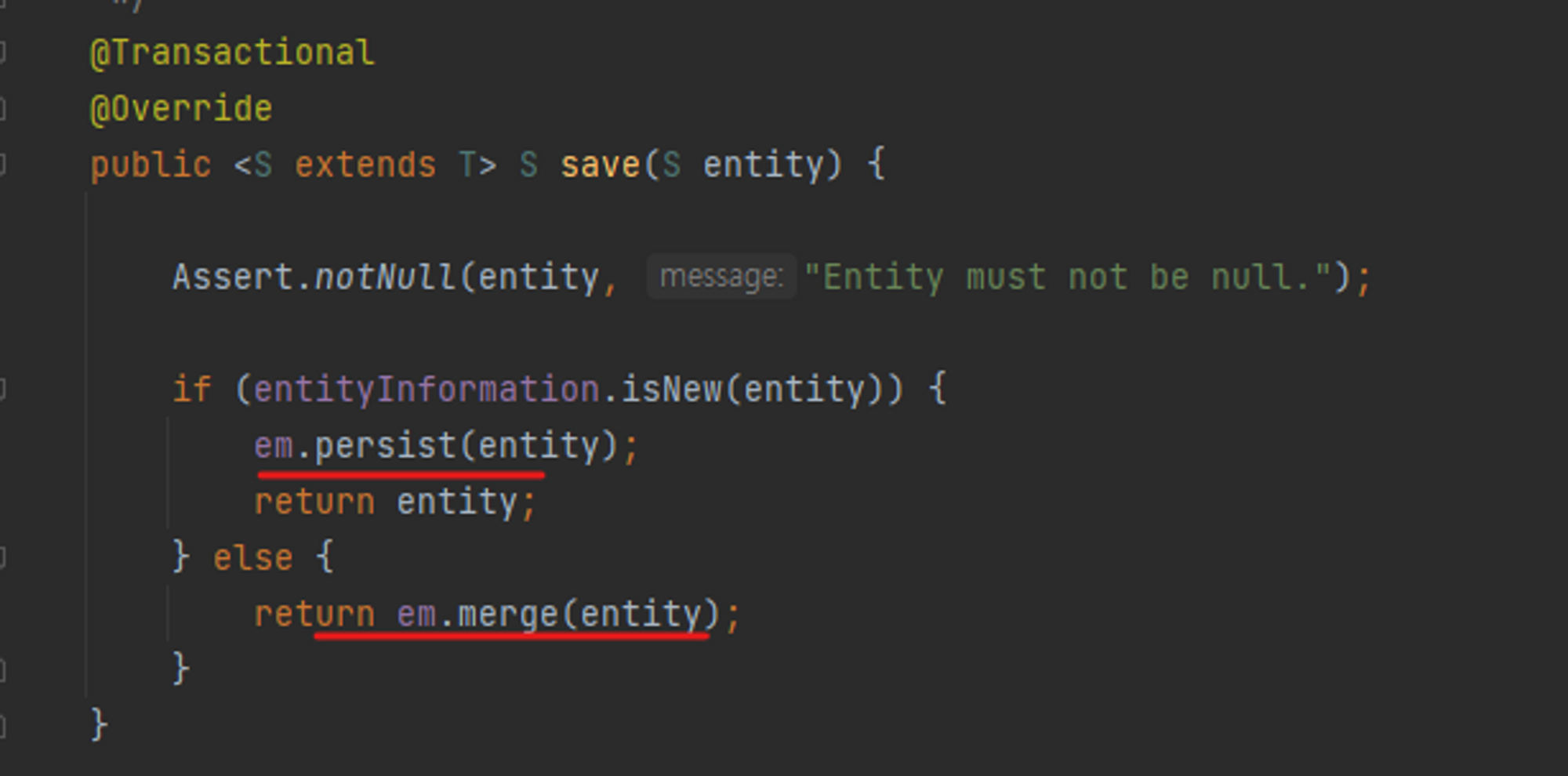
- 새로운 엔티티면 persist(저장)
- 새로운 엔티티가 아니면 병합(merge)
- merge는 DB에서 데이터를 가져와서 그 값을 바꿔치기 한다. 다만 변경감지와 달리 변경을 원하지 않았던 값에 null이 들어갈 위험이 있다.
- 따라서 가급적 merge보단 변경감지로 updategodi gksek.
- merge는 준영속상태에서 영속상태로 바꿀 때 쓰임.
merge 관련 자세한 내용은 [JPA 활용1] [5] 웹 계층 개발(하편) 참고
[2] 새로운 엔티티 구별하는 방법
'백엔드 > 스프링 데이터 JPA' 카테고리의 다른 글
| [Spring Data JPA] [7] 나머지 기능들 - Projections, 네이티브 쿼리 등 (0) | 2023.09.14 |
|---|---|
| [Spring Data JPA] [5] 확장 기능 (0) | 2023.09.10 |
| [Spring Data JPA] [4] 쿼리 메소드 기능(하편) - 페이징·벌크연산·EntityGraph (0) | 2023.09.09 |
| [Spring Data JPA] [4] 쿼리 메소드 기능(상편) (0) | 2023.09.08 |
| [Spring Data JPA] [3] 공통 인터페이스 기능 (0) | 2023.09.08 |
'백엔드/스프링 데이터 JPA' Related Articles
more



