
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- jpa 활용
- 실무활용
- JPA
- 불변 객체
- 프로젝트 환경설정
- 임베디드 타입
- Spring Data JPA
- 스프링
- 스프링 데이터 JPA
- 페이징
- 로그인
- JPA 활용2
- Bean Validation
- 기본문법
- 타임리프
- 스프링MVC
- 값 타입 컬렉션
- JPA 활용 2
- 김영한
- 타임리프 문법
- 트위터
- 일론머스크
- 벌크 연산
- 컬렉션 조회 최적화
- 예제 도메인 모델
- 스프링 mvc
- QueryDSL
- 검증 애노테이션
- JPQL
- API 개발 고급
- Today
- Total
RE-Heat 개발자 일지
[Spring Data JPA] [4] 쿼리 메소드 기능(하편) - 페이징·벌크연산·EntityGraph 본문
[Spring Data JPA] [4] 쿼리 메소드 기능(하편) - 페이징·벌크연산·EntityGraph
RE-Heat 2023. 9. 9. 21:46실전! 스프링 데이터 JPA - 인프런 | 강의
스프링 데이터 JPA는 기존의 한계를 넘어 마치 마법처럼 리포지토리에 구현 클래스 없이 인터페이스만으로 개발을 완료할 수 있습니다. 그리고 반복 개발해온 기본 CRUD 기능도 모두 제공합니다.
www.inflearn.com
인프런 김영한 님의 강의를 듣고 작성한 글입니다.
[7] 순수 JPA 페이징과 정렬
예제코드 조건
- 검색 조건 : 나이가 10살
- 정렬 조건 : 이름으로 내림차순
- 페이징 조건 : 첫 번째 페이지, 페이지당 보여줄 데이터는 3건
MemberJpaRepository
public List<Member> findByPage(int age, int offset, int limit){
return em.createQuery("select m from Member m where age = :age order by m.username desc")
.setParameter("age", age)
.setFirstResult(offset) //어디서부터 가져올 건가?
.setMaxResults(limit) // 개수 몇 개 가져올 건가?
.getResultList();
}
public long totalCount(int age){
return em.createQuery("select count(m) Member m where age = :age", Long.class)
.setParameter("age", age)
.getSingleResult();
}
- 페이징을 위한 offset limit를 받고 정렬 조건인 age를 받아 수행
- totalCount : 같은 나이의 데이터 수가 몇 개인지 파악
MemberJpaRepositoryTest
@Test
public void paging() throws Exception {
//given
memberJpaRepository.save(new Member("member1", 10));
memberJpaRepository.save(new Member("member2", 10));
memberJpaRepository.save(new Member("member3", 10));
memberJpaRepository.save(new Member("member4", 10));
memberJpaRepository.save(new Member("member5", 10));
//when
List<Member> members = memberJpaRepository.findByPage(10, 1, 3);
long totalCount = memberJpaRepository.totalCount(10);
// 페이지 계산 공식 적용
// totalPage = totalCount / size
// 마지막 페이지
// 최초 페이지
//then
assertThat(members.size()).isEqualTo(3);
assertThat(totalCount).isEqualTo(5);
}
SQL문
① findByPage()

② totalCount()

- setFirstResult()에 넘기는 offset을 1로 맞춘 후 날아간 SQL문
- 만일 setFirstResult(0)이면 offset을 넣는 게 의미가 없어서 offset 조건을 넣지 않는다.
[8] 스프링 데이터 JPA 페이징과 정렬
페이지 계산 공식 등을 스프링 데이터 JPA의 페이징 기능이 알아서 제공해 줘서 쓰기 편하다.
■ 페이징과 정렬파라미터
- org.springframework.data.domain.Sort : 정렬기능
- org.springframework.data.domain.Pageable : 페이징 기능 (내부에 Sort 포함)
■ 특별한 반환 타입
- org.springframework.data.domain.Page : 추가 count 쿼리 결과를 포함하는 페이징
- org.springframework.data.domain.Slice : 추가 count 쿼리 없이 다음 페이지만 확인 가능(내부적
으로 limit + 1 조회) - List (자바 컬렉션): 추가 count 쿼리 없이 결과만 반환
참고] Slice는 더 보기 등에서 사용된다.
■ 페이징과 정렬 사용 예제
검색 조건 : 나이가 10살
정렬 조건 : 이름으로 낼미차순
페이징 조건 : 첫 번째 페이지, 페이지당 보여줄 데이터는 3건
MemberRepository - 스프링 데이터 JPA 적용
public interface MemberRepository extends Repository<Member, Long> {
Page<Member> findByAge(int age, Pageable pageable);
}
MemberRepositoryTest
@Test
public void paging() throws Exception {
//given
memberRepository.save(new Member("member1", 10));
memberRepository.save(new Member("member2", 10));
memberRepository.save(new Member("member3", 10));
memberRepository.save(new Member("member4", 10));
memberRepository.save(new Member("member5", 10));
int age = 10;
PageRequest pageRequest = PageRequest.of(0, 3, Sort.by(Sort.Direction.DESC, "username"));
//when
Page<Member> page = memberRepository.findByAge(age, pageRequest);
//then
List<Member> content = page.getContent();
long totalElements = page.getTotalElements();
assertThat(content.size()).isEqualTo(3);
assertThat(totalElements).isEqualTo(5);
assertThat(page.getNumber()).isEqualTo(0); //페이지 번호
assertThat(page.getTotalPages()).isEqualTo(2);//전체 페이지 개수 3, 2 => 총 2개
assertThat(page.isFirst()).isTrue(); //첫 번째 페이지인가?
assertThat(page.hasNext()).isTrue(); //다음 페이지 있는가?
}- 두 번째 파라미터인 Pageable은 인터페이스다. 실제 사용할 땐 해당 인터페이스를 구현한 PageRequest 객체를 사용한다.
- PageRequest.of() 첫 번째 파라미터엔 현재 페이지, 두 번째 페이지엔 조회할 데이터 수를 입력한다. 추가로 Sort.by()로 정렬 조건도 추가할 수 있다.
※ 주의 : Page는 0부터 시작이다.
Page를 쓰면 totalCount()를 만들지 않아도 totalCount를 얻기 위한 쿼리까지 같이 날린다. getTotalElements()로 그 값을 받아올 수 있다. 그 외에도 Page는 페이지 번호, 전체 페이지 개수, 첫 번째, 다음페이지 존재 여부 등 다양한 기능을 제공한다.
단, Slice를 쓰면 count쿼리는 날아가지 않는다.
■ count 쿼리 분리 가능

totalCount는 데이터가 많을수록 상당한 리소스를 소모한다. 만일 Page의 query문에 join을 하면 count SQL문도 필요 없는 조인을 한다. 이런 불편을 개선하기 위해 스프링 데이터 JPA는 count 쿼리 분리 기능을 제공한다.
MemberRepository - findByAge countQuery 분리
@Query(value = "select m from Member m left join m.team t",
countQuery = "select count(m) from Member m"
)
Page<Member> findByAge(int age, Pageable pageable);
실행결과

- count 쿼리가 조인 없이 나가는 것을 확인할 수 있다.
■ 페이지를 유지하면서 엔티티를 DTO로 반환하기
Page<Member> page = memberRepository.findByAge(age, pageRequest);
Page<MemberDto> map = page.map(member -> new MemberDto(member.getId(), member.getUsername(), member.getTeam().getName()));- 엔티티를 노출하지 말고 DTO로 반환하기 위해 map을 사용
[9] 벌크성 수정 쿼리
모든 직원의 연봉을 10% 인상할 땐 어떻게 해야 할까? 변경감지가 아닌 일괄적인 update가 필요할 때 쓰는 게 바로 벌크성 수정쿼리다.
■ 순수 JPA로 일괄 update
MemberJpaRepository
public int bulkAgePlus(int age){
return em.createQuery("update Member m set m.age = m.age +1 where m.age >= :age")
.setParameter("age", age)
.executeUpdate();
}- 20세 이상인 사람 확인 후 한 살씩 올려줌
- update 쿼리 작성 후엔 executeUpdate()로 실행해야 한다.
- 반환 값은 update가 반영된 레코드 수
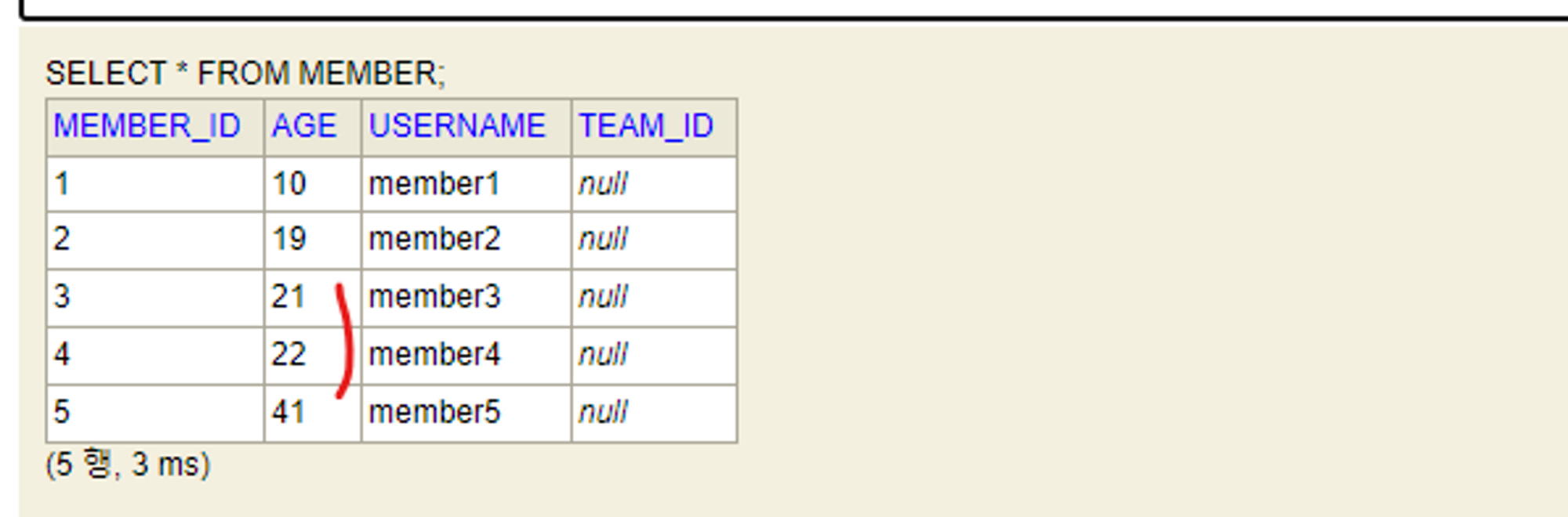
MemberJpaRepositoryTest
@Test
public void bulkUpdate(){
//given
memberJpaRepository.save(new Member("member1", 10));
memberJpaRepository.save(new Member("member2", 19));
memberJpaRepository.save(new Member("member3", 20));
memberJpaRepository.save(new Member("member4", 21));
memberJpaRepository.save(new Member("member5", 40));
//when
int resultCount = memberJpaRepository.bulkAgePlus(20);
//then
assertThat(resultCount).isEqualTo(3);
}
■ 스프링 데이터 JPA 적용
@Modifying
@Query("update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);- @Modifying을 써야 getSingleResult(), getResultList가 아닌 executeUpdate()가 실행된다.
- 벌크성 수정 쿼리에 @Modifying을 쓰지 않으면 QueryExecutionRequestException 오류가 뜬다.

■ 벌크성 수정 쿼리 사용 시 주의점
벌크성 /삭제 쿼리는 영속성 컨텍스트를 무시하고 바로 실행된다. 이 탓에 영속성 컨텍스트에 있는 엔티티 상태와 DB 엔티티의 상태가 달라질 수 있다.
① em.clear()하기 전


- DB의 age는 41세로 바뀌었으나 영속성 컨텍스트 값은 40세인 상태라 이런 일이 발생한다.
② em.clear() 적용


- em.clear()로 영속성 컨텍스트를 비운 뒤 조회하면 DB 값을 가져온다.
③ 스프링 데이터 JPA로 영속성 컨텍스트 초기화 하는 방법
MemberRepository
@Modifying(clearAutomatically = true)
@Query("update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);- @Modifying에 clearAutomatically 속성을 true로 바꿔주면 update 쿼리 후 영속성 컨텍스트를 자동으로 초기화해 준다.
▶ 권장 방안1. 영속성 컨텍스트에 엔티티가 없는 상태에서 벌크 연산을 먼저 실행한다.2. 부득이하게 영속성 컨텍스트에 엔티티가 있으면 벌크 연산 직후 영속성 컨텍스트를 초기화해야 한다.
[10] @EntityGraph
스프링 데이터 JPA가 제공하는 페치 조인을 간단하게 사용하는 방법이다.
페치 조인
=> 연관된 엔티티나 컬렉션을 한 번에 함께 조회하는 기능 - 지연로딩의 N + 1 문제 대부분 해결 가능
자세한 내용은 [JPA] [11] 객체지향 쿼리 언어 - 중급 문법 (상편) 확인
■ 순수 JPA 사용
@Query("select m from Member m join fetch m.team t")
List<Member> findMemberFetchJoin();- 페치 조인을 사용하면 필요한 걸 한 방에 가져와 N+1 문제를 해결할 수 있다.
test 코드 및 SQL
@Test
public void findMemberLazy(){
//given
//member1 -> teamA
//member2 -> teamB
Team teamA = new Team("teamA");
Team teamB = new Team("teamB");
teamRepository.save(teamA);
teamRepository.save(teamB);
Member member1 = new Member("member1", 10, teamA);
Member member2 = new Member("member1", 10, teamB);
memberRepository.save(member1);
memberRepository.save(member2);
em.flush();
em.clear();
//when
List<Member> members = memberRepository.findEntityGraphByUsername("member1");
for (Member member : members) {
System.out.println("member = " + member.getUsername());
System.out.println("member.teamClass = " + member.getTeam().getClass());
System.out.println("member.team = " + member.getTeam().getName());
}
//then
}
■ @EntityGraph 사용
JPQL로 join fetch를 계속 써주는 게 번거로울 때 쓰는 게 @EntityGraph다.
@Override
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();
@EntityGraph(attributePaths = {"team"})
@Query("select m from Member m")
List<Member> findMemberEntityGraph();
@EntityGraph(attributePaths = {"team"})
List<Member> findEntityGraphByUsername(@Param("username") String username);① findAll()
- @EntityGraph + @Override JpaRepository에 이미 존재하는 CRUD를 재정의 해서 사용한 방법.
- @EntityGraph의 attributePaths 속성에 {"team"}을 넣어주면 알아서 Member와 Team을 페치 조인해서 가져온다.


② findMemberEntityGraph()
- @EntityGraph + JPQL
- 내가 지정한 메소드 이름으로 페치 조인하는 방법이다.
③ findEntityGraphByUsername()
- @EntityGraph + 메서드 이름으로 쿼리
결론 : @EntityGraph는 사실상 페치 조인의 간편 버전이다.
■ NamedEntityGraph
@NamedQuery처럼 EntityGraph도 비슷한 기능을 제공한다.
Member 엔티티
@NamedEntityGraph(name = "Member.all", attributeNodes = @NamedAttributeNode("team"))
@Entity
public class Member {}
- @NameEntityGraph의 name 속성으로 이름을 지정하고, attributeNodes 속성으로 페치 조인할 team을 지정한다.
- 실무에선 거의 쓰이지 않는다.
결론
1. 간단한 페치 조인은 @EntityGraph 사용
2. 복잡하면 JPQL의 페치 조인을 쓰자.
[11] JPA Hint & Lock
■ JPA Hint
JPA는 일반적인 조회 시 변경 감지를 위한 스냅샷을 저장해 준다. 그런데 단순 조회라면 스냅샷을 저장해 리소스를 낭비할 필요가 없다. 이럴 때 사용하는 게 바로 JPA Hint다.
① 쿼리 힌트 사용
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
Member findReadOnlyByUsername(String username);- @QureyHints로 읽기 전용으로 지정
- 이렇게 하면 스냅샷을 만들지 않으므로(변경감지 X) 값이 바뀌어도 update쿼리가 날아가지 않는다.
② 쿼리 힌트 Page 추가 예제
@QueryHints(value = { @QueryHint(name = "org.hibernate.readOnly",
value = "true")},
forCounting = true)
Page<Member> findByUsername(String name, Pageable pageable);- org.springframework.data.jpa.repository.QueryHints 어노테이션을 사용
- forCounting : 반환타입으로 Page 인터페이스를 적용하면 추가로 호출하는 페이징을 위한 count 쿼리도 쿼리 힌트적용(기본값 true )
■ JPA Lock

- for update는 동시성 문제를 해결하기 위해 사용하는 방법. 자세한 내용은 따로 공부가 필요해 보인다.
- org.springframework.data.jpa.repository.Lock 어노테이션을 사용
- JPA가 제공하는 락은 JPA 책 16.1 트랜잭션과 락 절을 참고
'백엔드 > 스프링 데이터 JPA' 카테고리의 다른 글
| [Spring Data JPA] [6] 스프링 데이터 JPA 분석 (0) | 2023.09.13 |
|---|---|
| [Spring Data JPA] [5] 확장 기능 (0) | 2023.09.10 |
| [Spring Data JPA] [4] 쿼리 메소드 기능(상편) (1) | 2023.09.08 |
| [Spring Data JPA] [3] 공통 인터페이스 기능 (0) | 2023.09.08 |
| [Spring Data JPA] [2] 예제 도메인 모델 (0) | 2023.09.08 |



